Introducere în Colab
Varianta rulabilă a fișierului curent poate fi accesată aici: Introducere în Colab
Ce este Colab?
Colaboratory este o instanță Jupyter notebook accesibilă full online. Asta înseamnă că nu necesită setup și le permite utilizatorilor să creeze și să colaboreze împreună cu alții pe documente live care conțin cod rulabil, vizualizări și text explicativ.
În general este util pentru a scrie prototipuri și a rezolva probleme scurte, ușor de urmărit secvențial.
Există mai multe variante pentru a rula o secvență de cod după ce ai dat click pe ea:
- Apasă butonul de play din stânga acesteia
- Rulează
Shift + Enterpentru a trece la celula următoare - Rulează
Cmd / Ctrl + Enterpentru a rămâne în celula curentă
print('Hello World!')
Output: Hello World
Sub celulă a apărut outputul acestuia. Outputul poate fi valoarea returnată de celulă, o afișare / serie de afișări (print) sau nimic. Obiectele apelate direct sau operațiile returnează o valoare, atribuirile nu apelează nimic:
'Hello World'
Output: Hello World
5 * 3
Output: 15
x = 6 * 4
Observi numărul care a apărut în stânga celulelor de până acum? Are forma: [1]. În colab putem rula celulele de mai multe ori, în orice ordine ne dorim. Acel număr ne indică ultimul indice de rulare corespunzător celulei - util pentru a ne da seama în proiecte mai mari care a fost ultima celulă rulată sau care a fost ordinea în care am rulat anumite celule.
Variabilele definite într-o celulă pot fi utilizate în orice celulă apelată ulterior, indiferent de poziția acesteia. Folosește săgeata în sus de pe celula de mai jos pentru a o muta deasupra atribuirii și observă rezultatul rulării acesteia:
x
Output: 24
Până acum am aflat că toate variabilele definite liber sunt globale. Rulări repetate neintenționate pot duce la confuzie în cod. Uneori aceasta poate fi rezolvată prin resetarea tuturor variabilelor globale:
%reset -f
Observi operatorul % pus la începutul liniei? Acesta anunță că vrem să folosim o funcție magică. Puteți afla mai multe detalii despre aceste funcții dacă apelați celula de mai jos:
%magic
O altă modalitate de a interacționa cu environmentul este cu ajutorul comenzii !. O putem folosi atât pentru a accesa poziția noastră în cloud cât și pentru a instala diverse pachete cu !pip install <librărie>.
!ls
Output: sample_data
Ce este sample_data?
În stânga paginii ai un buton de files care îți arată unde te afli. Atenție: Nu apăsa pe .. din directorul default, dar dacă o faci din greșeală îți poți accesa fișierele apăsând pe /content.
Directorul sample_data conține o serie de fișiere cu care te poți juca până te familiarizezi cu Colab. Citește fișierul README.md pentru mai multe detalii despre datele oferite.
Poți folosi drag & drop sau butonul de add files pentru a adăuga un fișier în sesiunea curentă. Dacă vrei să păstrezi fișierul pentru mai mult timp (sau să accesezi un fișier deja salvat) te poți conecta la contul tău Google Drive rulând codul de mai jos:
from google.colab import drive
drive.mount('/content/drive/')
Output: Mounted at /content/drive/
De aici poți citi / scrie fișiere în root-ul drive-ului tău personal (rădăcina arborelui de fișiere), într-o locație custom scriind calea până la aceasta de fiecare dată, sau poți seta noul root în locația dorită folosind librăria os:
import os
os.chdir("/content/drive/MyDrive/Cram School")
Notebook-urile Colab pot fi shared cu view access sau cu edit access. Cum ne afectează asta:
- Edit access: pe măsură ce modifici celule acestea se modifică automat pentru toate persoanele care au orice fel de drept la acest fișier
- View access: poți face modificări direct pe fișier, dar nu se salvează automat. Le poți salva cu
Ctrl + S, conectându-te la drive-ul personal folosind codul de mai sus, sau copiind pe drive-ul personal cu ajutorul butonului din headerul paginii: Copy to Drive. În practică toate aceste metode fac exact același lucru.
Pentru a crea celule noi poți folosi butoanele + Code și + Text. Le poți accesa din headerul paginii sau după ce faci hover pe linia dintre 2 celule.
Mai multe resurse despre Colab Notebooks și cum poate fi folosit pentru Data Visualisation și Machine Learning aici: Welcome to Colaboratory
Cum Facem un Proiect?
Colab este un instrument util și ușor de urmărit pentru proiecte mici sau laboratoare, dar atunci când avem de făcut un proiect mai complex ne poate ajuta mai mult să ne mutăm pe un IDE local, caz în care e bine să respectăm anumite convenții.
1. Modularizare
Cel mai important lucru într-un proiect complex este modularizarea. Cu cât avem mai multe funcționalități cu atât devine mai greu de urmărit un proiect care se întinde mult în același fișier sau care nu are suficiente clase și funcții. Așadar ne vom folosi de următoarele elemente:
- virtual environment — un loc magic unde se instalează toate librăriile necesare proiectului curent, fără a ne încărca memoria laptopului / calculatorului. Putem să ne creăm un virtual environment manual rulând în consolă:
pip install virtualenv # instalăm virtualenv
python -m venv env # creăm folderul în care vom salva datele
source env/bin/activate # activăm environmentul
- clase — dacă vrem să repetăm o funcționalitate, ne e mult mai ușor să o declarăm direct într-o clasă, împreună cu funcțiile aferente. În general ne dorim să facem o clasă pentru fiecare componentă cu rol diferit (ex: embedding, antrenare).
- fișiere — pentru a parcurge și mai ușor codul ne ajută să îl împărțim în multe fișiere în funcție de funcționalitate. O împărțire intuitivă ar fi să avem fișiere diferite pentru clase diferite plus un fișier main care le apelează.
2. Readability
Dacă plănuim să îi arătăm cuiva codul vreodată sau ne așteptăm să îl recitim în câteva luni / câțiva ani este destul de important să poată fi citit fără a necesita alte explicații. Din fericire nu ne trebuie o mașină a timpului dacă respectăm următoarele:
- denumiri competente pentru clase, funcții, variabile etc. — ce trebuie să avem în vedere aici este “Cât i-ar lua unui coleg oarecare să înțeleagă pe cont propriu ce se întâmplă?”. Putem merge chiar mai departe și să începem fiecare funcție cu o secțiune de comentarii unde explicăm ce face funcția în câteva cuvinte, ce fac parametrii și ce returnăm la final, de exemplu:
def maxim(a, b, c):
""" Calculează maximul între 3 numere.
:param a: o variabilă de tip int
:param b: o variabilă de tip long
:param c: o variabilă de tip long long
:return: elementul cu valoarea cea mai mare
"""
return max(a, b, c)
- README.md — un fișier în care scriem un scurt overview al proiectului curent, ce clase apar în fiecare fișier și cum sunt legate între ele, ce structură are proiectul și ce comenzi trebuie rulate pentru a-l porni.
- requirements.txt — un fișier care conține lista librăriilor utilizate în proiect împreună cu versiunea pe care am lucrat. Acesta poate fi extras automat folosind comanda:
py -m pip freeze > requirements.txt
3. Istoric
Doar pentru că ne-am mutat în local pentru un proiect mai complex nu înseamnă că trebuie să rămână local. În continuare putem lucra împreună cu mai mulți oameni pe același proiect online folosind git (Tutorial Git).
- git — un instrument foarte puternic pentru a păstra istoricul tuturor modificărilor și pentru a crea un portofoliu online cu proiectele făcute până acum. Există 2 site-uri foarte cunoscute pe care le puteți utiliza: Tutorial GitHub și Tutorial GitLab. Ambele sunt la fel de bune, alegerea ține de preferința personală.
- .gitignore — un fișier care conține lista folderelor și fișierelor pe care nu vrem să le salvăm în online. Acesta va include o serie de foldere cu configurări locale (__pycache__/, .idea/), variabile de sistem (env/) chei secrete (secret_key.txt) sau alte fișiere pe care nu vrem să le publicăm din diverse motive.
Introducere în Python
Varianta rulabilă a fișierului curent poate fi accesată aici: Introducere în Python
Python este un limbaj de programare simplu. Nu folosim ; la final de instrucțiune, ci terminăm instrucțiunile la final de rând. Nu folosim {} pentru a secvenția bucăți de cod, ci le scriem după :. Ce este foarte important, în schimb, este indentarea. Pentru a declara că o bucată de cod se află în interiorul unei funcții, clase, instrucțiuni etc. aceasta trebuie să fie aliniată cu un tab în plus față de header:
if True:
print("Sunt într-un if!")
print("Sunt înafara if-ului!")
Output:
Sunt într-un if!
Sunt înafara if-ului!
Curs 1
Afișare “pe ecran”
Observați afișările de mai sus. Folosind funcția print putem afișa orice tip de date pus între paranteze. Nu este obligatoriu să afișăm o singură variabilă, putem afișa oricât de multe dacă punem , între ele:
print()
print('Ana are mere.')
Output: Ana are mere.
print(3, 6 + 2)
Output: 3 8
Variabile
Toate variabilele în Python sunt obiecte. Asta înseamnă că le puteți atribui orice valoare fără a preciza tipul de date, și chiar să actualizați valoarea unei variabile cu un tip de date diferit fără probleme:
x = 3
y = 2.15
print(x, y)
x = "abc"
print(x)
Output:
3 2.15
abc
Tipuri de date
Putem considera fiecare variabila o cutie. Cutia are un nume (x, y etc.) si un element inauntru (23, “doi” etc.). Putem vedea tipul de date folosind functia type:
x = 23
type(x)
Output: int
y = 6.3
type(y)
Output: float
z = "doi"
type(z)
Output: str
Cele mai simple tipuri de date sunt cele de mai sus:
- int (integer) = numar intreg (fara virgula)
- float (floating point) = numar cu virgula
- char (character) = orice caracter de pe tastatura. In Python nu exista explicit, dar il avem in alte limbaje de programare
- str (string) = sir de caractere. Un cuvant, un paragraf etc.
Operatii
x = 23
y = 12
print("x =", x)
print("y =", y)
print("x + y =", x + y)
print("x - y =", x - y)
print("x * y =", x * y)
Output:
x = 23
y = 12
x + y = 35
x - y = 11
x * y = 276
Catul impartirii lui x la y:
print("x // y =", x // y)
Output: x // y = 1
Restul impartirii lui x la y:
print("x % y =", x % y)
Output: x % y = 11
Putem folosi catul si restul impartirii la 10 (sau multipli de 10) pentru a selecta diferite cifre din numar. De exemplu:
x = 65273
print("Cifra unitatilor:", x % 10)
print("Ultimele 2 cifre:", x % 100)
print("Ultimele 3 cifre:", x % 1000)
Output:
Cifra unitatilor: 3
Ultimele 2 cifre: 73
Ultimele 3 cifre: 273
print("Numarul fara cifra unitatilor:", x // 10)
print("Fara ultimele 2 cifre:", x // 100)
print("Fara ultimele 3 cifre:", x // 1000)
Output:
Numarul fara cifra unitatilor: 6527
Fara ultimele 2 cifre: 652
Fara ultimele 3 cifre: 65
Conversie de tip
a = input("Scrie un numar: ")
print(a, type(a))
Output: 34 <class 'str'>
b = int(a)
print(b, type(b))
Output: 34 <class 'int'>
Citire “de la tastatura”
Folosim funcția input pentru a citi o linie de la tastatură. Fiecare linie e citită ca un element de tip string (un text), chiar dacă are doar numere. Pentru a putea manipula ce am citit ca orice alt tip de date va trebui să îi facem conversie de tip.
x = input()
print(x, 'are tipul', type(x))
Output: 2 are tipul <class 'str'>
x = input()
y = int(x)
print('x =', x, 'are tipul', type(x))
print('int(x) =', y, 'are tipul', type(y))
Output:
x = 3 are tipul <class 'str'>
int(x) = 3 are tipul <class 'int'>
Citirea mai multor numere “de la tastatura”
x = input()
print("input:", x)
x = x.split()
print("x.split():", x)
a = x[0]
b = x[1]
print("a =", a, ", b =", b)
print("a + b =", a + b)
a = int(a)
b = int(b)
print("a + b =", a + b)
Output:
input: 3 56
x.split(): ['3', '56']
a = 3 , b = 56
a + b = 356
a + b = 59
Exerciții
sum00, Urare, scadere2, asii, uciv
Temă
Curs 2
Exerciții
Ridicarea la putere:
x = 2
y = 5
print("x ** y =", x ** y)
Output: x ** y = 32
Exerciții
Tipul de date float (numere raționale)
type(123.45)
Output: float
Conversie la tipul float:
a = "123.45"
print(a, type(a))
b = float(a)
print(b, type(b))
Output:
123.45 <class 'str'>
123.45 <class 'float'>
Exerciții
Temă
Toate problemele medii de la Operatori și Expresii
Curs 3
Tipul de date boolean
print(3 == 4, 3 != 4)
Output: False True
type(True)
Output: bool
| a | b | a and b | a or b |
|---|---|---|---|
| True | True | True | True |
| True | False | False | True |
| False | True | False | True |
| False | False | False | False |
Structura de decizie
if True:
print("Adevărat")
if 4 == 4:
print("egale")
else:
print("diferite")
Output: egale
a = 9
b = 3
if a > b:
print("mai mare")
elif a < b:
print("mai mic")
else:
print("egale")
Exerciții
Citește un număr de la tastatură. Afișează-l pe ecran dacă este strict mai mare decât 10.
Afișează DA dacă un număr e multiplu de 3, NU altfel.
Problema paritate:
Citește un număr n de la tastatură. Afișează pe ecran mesajul n este par dacă este par, respectiv n este impar în caz contrar (în locul literei “n” va apărea valoarea numărului, ca în exemplu).
Problema max2:
Citește 2 numere de la tastatură și afișează-l pe cel mai mare dintre ele.
Problema Interval2:
Citește 3 numere de la tastatură (a b x). Afișează DA dacă numărul x aparține intervalului [a, b] (este mai mare sau egal cu a și mai mic sau egal cu b) și NU altfel.
Parametrul end
print(3)
print(4)
print(3, end=' ')
print(4, end=' ')
print()
print(3, end=' * ')
print(4, end='!')
Structuri repetitive
for i in range(1, 3):
print("Happy Birthday!")
Output:
Happy Birthday!
Happy Birthday!
for i in range(1, 10, 1):
print(i, end=' ')
Output: 1 2 3 4 5 6 7 8 9
for i in range(1, 10, 2):
print(i, end=' ')
Output: 1 3 5 7 9
for i in range(10, 0, -1):
print(i, end=' ')
Output: 10 9 8 7 6 5 4 3 2 1
Exerciții
Curs 4
Listele sunt seturi ordonate de elemente și se enumeră între paranteze pătrate.
Dacă adunăm două liste obținem concatenarea lor:
[1,2] + [3,4]
Output: [1, 2, 3, 4]
Dacă înmulțim o listă cu un număr n, obținem o listă nouă în care se repetă șirul inițial de n ori:
[1,2] * 4
Output: [1, 2, 1, 2, 1, 2, 1, 2]
Crearea unei liste
Se enumeră elementele între paranteze drepte, sau se folosește constructorul list care primește un obiect prin care se poate itera (precum un sir de caractere):
l1 = [1,2,3]
l2 = list("abc")
print(l1)
print(l2)
Output:
[1, 2, 3]
['a', 'b', 'c']
Funcțiile unei liste
Lungimea unei liste se calculează cu len(lista):
len([10,5,1])
Output: 3
Putem afla cel mai mare element dintr-o listă cu max(lista):
max([1, 10, 5])
Output: 10
Pentru șiruri de caractere maximul este luat lexicografic:
max(['ana', 'are', 'mere', 'și', 'pere'])
Output: 'și'
Putem afla cel mai mic element dintr-o listă folosind funcția min(lista):
min([20, 2, 3, 10])
Output: 2
Asemănător calculăm suma elementelor dintr-o listă:
sum([20, 10, 3])
Output: 33
Exerciții
Temă
Indicii unei liste
Indicii unei liste încep de la 0:
l = [10, 5, 1]
print('l[0] :', l[0])
print('l[2] :', l[2])
Output:
l[0] : 10
l[2] : 1
Putem folosi și indici negativi. Indicii negativi îi putem considera pornind de la dreapta spre stânga începând cu -1, și tot avansând cu 1 spre stânga:
l = [10, 5, 1]
print('l[-1] :', l[-1])
print('l[-2] :', l[-2])
print('l[-3] :', l[-3])
Output:
l[-1] : 1
l[-2] : 5
l[-3] : 10
Adăugarea elementelor într-o listă
La finalul listei - metoda append(element):
l = [10, 7, 3, 5]
l.append(2)
print(l)
Output: [10, 7, 3, 5, 2]
La o poziție dată - metoda insert(indice, element):
l = [10, 7, 3, 5]
l.insert(1, 122)
print(l)
Output: [10, 122, 7, 3, 5]
Ștergerea elementelor dintr-o listă
Pentru a șterge elementul de la poziția indice: pop(indice). Utilizarea fără argumente este echivalentă apelării cu indicele -1 (ultimul element):
l = [10, 7, 3, 5]
l.pop(2)
print(l)
Output: [10, 7, 5]
Fără parametri:
l=[10,7,3,5]
l.pop()
print(l)
Output: [10, 7, 3]
Putem șterge prima instanță a unui anumit element: remove(element):
l = [10, 7, 3, 5]
l.remove(7)
print(l)
Output: [10, 3, 5]
Sortarea unei liste
Sortarea unei liste se poate face simplu prin metoda sort():
l = [2, 1, 10, 4, 100, 17, 23]
l.sort()
print(l)
Output: [1, 2, 4, 10, 17, 23, 100]
Sortarea implicită este cea crescătoare. Pentru a sorta descrescător, putem folosi parametrul reverse al funcției sort cu valoarea True:
l = [2, 1, 10, 4, 100, 17, 23]
l.sort(reverse = True)
print(l)
Output: [100, 23, 17, 10, 4, 2, 1]
Putem sorta oricum dorim folosind aceeași funcție. De exemplu, pentru sortarea după ultima cifră a numerelor vom folosi funcția lambda:
l = [2, 1, 10, 4, 100, 17, 23]
l.sort(key = lambda x: x % 10)
print(l)
Output: [10, 100, 1, 2, 23, 4, 17]
Citirea unei liste de numere
l = list(map(int, input().split()))
print(l)
Output: [3, 4, 5]
Parcurgerea unei liste
Putem parcurge o listă în mai multe moduri. Operatorul in permite iterarea prin fiecare element al listei fără a cunoaște indicele elementului:
for elem in l:
print(elem)
Output:
10
5
1
Dacă ne interesează indicele elementului putem parcurge lista folosindu-ne de accesul direct al elementului prin indice:
for i in range(len(l)):
print(l[i])
Output:
10
5
1
Putem itera printr-o listă folosind enumerate(lista) care este un generator prin care obținem pe rând tupluri de forma (indice, lista[indice]) - indicele din listă și elementul corespunzător acestuia:
for i, elem in enumerate(l):
print(i, elem)
Output:
0 3
1 4
2 5
Exerciții
Curs 5
Subliste (sliceuri)
Pentru a obține o sublistă dintr-o listă putem folosi notația l[indiceStart:indiceFinal] care va oferi sublista cu elementele din lista inițială cuprinse între pozițiile indiceStart inclusiv și indiceFinal exclusiv.
Dacă dorim un mod de parcurgere a listei diferit de cel implicit, pentru a crea sublista, putem adăuga și parametrul de iterare: l[indiceStart:indiceFinal:iterator].
Astfel se va porni de la indicele de Start, punând elementul corespunzător în sublistă, si la indiceStart se va aduna apoi iteratorul, generând urmatorul element din sublistă. Procedeul se va repeta până se ajunge la un indice mai mare sau egal cu indicele final (pentru această ultimă valoare care depășește limita dată de indicele final nu se mai generează element în sublistă).
Oricare dintre cele trei argumente poate lipsi, caz în care se iau valorile implicite - indiceStart ia valoarea 0, indiceFinal ia lungimea listei și iteratorul devine 1.
Exemple:
l = list(range(10))
l
Output: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
list(range(2, 8, 2))
Output: [2, 4, 6]
l[2:8]
Output: [2, 3, 4, 5, 6, 7]
l[2:8:2]
Output: [2, 4, 6]
l[-1:-7]
Output: []
l[-1:-7:-1]
Output: [9, 8, 7, 6, 5, 4]
l[8:2:-1]
Output: [8, 7, 6, 5, 4, 3]
l[:5]
Output: [0, 1, 2, 3, 4]
l[4:]
Output: [4, 5, 6, 7, 8, 9]
l[:]
Output: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Observați că putem folosi și indici negativi, dar dacă vrem o parcurgere de la dreapta la stânga, trebuie să folosim un iterator negativ.
Întrucât toate variabilele în Python sunt obiecte, puteți crea o listă cu variabile de tipuri diferite:
l = ['z', 1, "mac-mac", 3.14, []]
print(l)
Output: ['z', 1, 'mac-mac', 3.14, []]
Pentru următoarele exemple încercați să vă dați seama ce o să afișeze înainte de a le apela:
print(l[1:3])
print(l[3:])
print(l[:3])
print(l[1:9:2])
print(l[-2])
print(l[:-1])
Output:
[1, 'mac-mac']
[3.14, []]
['z', 1, 'mac-mac']
[1, 3.14]
3.14
['z', 1, 'mac-mac', 3.14]
Exerciții
Folosind doar slice-uri, afișează elementele listei date în ordine inversă.
Soluție:
# Soluție
l[::-1]
Output: [[], 3.14, 'mac-mac', 1, 'z']
List comprehension
Au sintaxa de forma:
[expresie for element in obiect_iterabil]
caz in care se va genera o listă cu același număr de elemente precum obiectul iterabil, sau:
[expresie for element in obiect_iterabil if conditie]
caz în care va avea în listă doar elementele din obiectul iterabil care îndeplinesc condiția.
Exemple:
l = [2, 7, 5, 23, 10]
Lista cu dublul elementelor lui l:
l = []
for i in range(1, 10):
l.append(i)
print(l)
Output: [1, 2, 3, 4, 5, 6, 7, 8, 9]
l = list(range(1, 10))
print(l)
Output: [1, 2, 3, 4, 5, 6, 7, 8, 9]
l = [i for i in range(1, 10)]
print(l)
Output: [1, 2, 3, 4, 5, 6, 7, 8, 9]
l = [i if i < 5 else i + 1 for i in range(1, 10) if i % 2 == 0]
print(l)
Output: [2, 4, 7, 9]
Lista cu perechile de vecini din l:
l2 = [[l[i], l[i + 1]] for i in range(len(l) - 1)]
l2
Output: [[2, 7], [7, 5], [5, 23], [23, 10]]
Lista produsului cartezian:
l3 = [[x, y] for x in l for y in l]
l3
Output:
[[2, 2], [2, 7], [2, 5], [2, 23], [2, 10],
[7, 2], [7, 7], [7, 5], [7, 23], [7, 10],
[5, 2], [5, 7], [5, 5], [5, 23], [5, 10],
[23, 2], [23, 7], [23, 5], [23, 23], [23, 10],
[10, 2], [10, 7], [10, 5], [10, 23], [10, 10]]
Lista elementelor pare:
l4 = [x for x in l if x % 2 == 0]
l4
Output: [2, 10]
Crearea unei matrici folosind comprehensions. Putem folosi un comprehension cu for dublu. De exemplu dacă dorim o matrice formată doar din 0-uri:
l = [[0] * 5 for _ in range(10)]
print(l)
Output: [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], ...]
Atenție, frecvent se face greșeala următoare:
l = [[0] * 5] * 10
print(l)
l[0][0] = 111
print(l)
Output:
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], ...]
[[111, 0, 0, 0, 0], [111, 0, 0, 0, 0], ...]
Observați cum s-a schimbat primul element în fiecare listă?
Atunci cand apelăm lista * n, unde n e un număr natural nenul, se copiază elemente din listă de n ori. Problema apare când avem o listă de obiecte, deoarece se copiază referențele către acele obiecte. Practic am avut [lista_de_0] * 10, care a dus la o listă cu 10 referințe către aceeași lista de 0-uri, deci când am schimbat primul element din prima listă am văzut modificarea în toate cele 10 liste fiindcă de fapt sunt toate același obiect.
Varianta corectă:
l = [[0] * 5 for i in range(10)]
print(l)
l[0][0] = 111
print(l)
Output:
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], ...]
[[111, 0, 0, 0, 0], [0, 0, 0, 0, 0], ...]
Exerciții
Rezolvă folosind list comprehension:
Curs 6
Mulțimi
Mulțimile reprezintă seturi de elemente neordonate care nu acceptă duplicate.
Crearea unei mulțimi:
multime_vida = set()
print(multime_vida)
Output: set()
multime = {2, 3, 10, 8}
print(multime)
Output: {8, 3, 10, 2}
Observați că nu s-a păstrat ordinea din inițializarea mulțimii, fiindcă mulțimile sunt neordonate.
Pentru a obține cardinalul unei mulțimi se folosește funcția len():
len({2, 4, 10})
Output: 3
Pentru a adăuga un element într-o mulțime se folosește funcția add:
multime_vida.add(5)
multime_vida.add(8)
print(multime_vida)
Output: {8, 5}
Pentru a reuni 2 mulțimi se folosește funcția union:
multime = multime.union(multime_vida)
print(multime)
Output: {2, 3, 5, 8, 10}
Mai multe funcții cu mulțimi găsiți aici.
my_set = set()
my_set.add(3)
print("My first set: ", my_set)
my_second_set = set([2, 6, 3, 2])
print("My second set: ", my_second_set)
print("Set union: ", my_set.union(my_second_set))
print("Set intersection: ", my_set.intersection(my_second_set))
Output:
My first set: {3}
My second set: {2, 3, 6}
Set union: {2, 3, 6}
Set intersection: {3}
Dicționare
Dicționarele reprezintă un set de perechi de chei și valori asociate. Cheile sunt unice în dicționar și trebuie să fie de tip immutable (pot fi stringuri, numere, tupluri etc., dar nu pot fi liste).
Pentru a crea un dicționar vid, folosim:
d = {}
Pentru a adăuga chei noi în dicționar, putem pur și simplu să le atribuim o valoare. Sintaxa este: dictionar[cheie] = valoare.
d["a"] = 100
d["b"] = 200
d["c"] = 300
print(d)
Output: {'a': 100, 'b': 200, 'c': 300}
Pentru a itera prin cheile unui dicționar putem folosi operatorul in:
for k in d:
print(k, d[k])
Output:
a 100
b 200
c 300
Pentru a verifica dacă o cheie se găsește într-un dicționar, putem folosi același operator:
print("a" in d)
print(100 in d)
Output:
True
False
sau să folosim metoda items() care returnează o listă cu tupluri de forma (cheie, valoare):
for k, v in d.items():
print(k, v)
Output:
a 100
b 200
c 300
Pentru a obține lista de chei putem folosi metoda keys() iar pentru lista de valori metoda values().
print(d.keys())
Output: dict_keys(['a', 'b', 'c'])
print(d.values())
Output: dict_values([100, 200, 300])
Mai multe funcții pe dicționare găsiți aici.
my_dict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
print("My first dictionary: ", my_dict)
my_second_dict = dict(name = "John", age = 36)
print("My second dictionary: ", my_second_dict)
print()
my_second_dict["country"] = "Norway"
print("We can easily add new fields: ", my_second_dict)
my_second_dict["country"] = "Italy"
print("Or modify them: ", my_second_dict)
Output:
My first dictionary: {'brand': 'Ford', 'model': 'Mustang', 'year': 1964}
My second dictionary: {'name': 'John', 'age': 36}
We can easily add new fields: {'name': 'John', 'age': 36, 'country': 'Norway'}
Or modify them: {'name': 'John', 'age': 36, 'country': 'Italy'}
Exerciții
Temă
Proiect
Scrie un meniu de cumparaturi. Pe ecran se va afisa o lista de produse si se va deschide un input in care utilizatorul va scrie ce produs isi doreste sa cumpere.
Pentru input gresit se va afisa mesaj de eroare.
Pentru input corect utilizatorul va fi intrebat cate produse isi doreste si va fi acceptat doar input numeric in intervalul 1-100.
Programul se va opri la citirea inputului “exit” si va afisa lista de cumparaturi si pretul total al acestora.
Elemente avansate de Python
Varianta rulabilă a fișierului curent poate fi accesată aici: Elemente avansate de Python
Funcții
Funcțiile se definesc cu ajutorul cuvântului def. Pot avea oricât de mulți parametri, și pot returna oricât de multe valori. Parametrii pot avea valori implicite, dar restricțiile de tip sunt mai mult pentru developer – nu vor arunca erori dacă nu sunt respectate.
def f(age: int, name = "Bran") -> str:
pass
f('Age')
Valorile implicite se află mereu la finalul listei de parametri.
Obervați cuvântul cheie pass folosit mai sus. Este o expresie vidă care poate fi utilizată în interiorul unei structuri pentru a nu arunca eroare până o completăm cu instrucțiunile dorite. O putem folosi atunci când vrem să scriem întâi headerele funcțiilor / claselor.
Clase
Clasele se definesc cu ajutorul cuvântului cheie class. Ca în orice limbaj, avem variabile statice pe care le putem apela fie la nivel de clasă, fie la nivel de instanță a clasei:
class Clasa:
x = 10
Clasa.x
Output: 10
instanta = Clasa()
instanta.x
Output: 10
Cu ce seamănă clasele din ce ați mai făcut până acum?
…
Funcțiile din clase încep mereu cu operatorul self – referință către clasa respectivă. Referința poate avea orice denumire, self este doar o convenție.
class Clasa:
x = 3
def f(self, x):
return self.x, x
instanta = Clasa()
instanta.f(7)
Output: (3, 7)
Observă cum x și self.x sunt variabile complet separate. În Python, parametrii funcțiilor mereu sunt considerați independenți de mediul exterior, în timp ce elementele care încep cu self. sunt specifici instanței clasei respective.
Pe lângă funcțiile normale avem și o serie de funcții implicite:
- __init__ -> inițializarea clasei (constructor)
- __str__ -> transformarea clasei în instanță string
- __lt__ -> definiția operatorului <
- __le__ -> definiția operatorului <=
- __gt__ -> definiția operatorului >
Funcțiile pot fi apelate cu denumirea lor, dar și direct, folosind simbolul respectiv.
class Clasa:
def __init__(self, x):
self.x = x
def __str__(self):
return "Valoarea clasei: " + str(self.x)
instanta = Clasa(5)
print(instanta)
Output: Valoarea clasei: 5
EXERCIȚIU
Creează o clasă cu minim 2 elemente. Creează 2 instanțe pentru noua clasă și afișeaz-o pe cea mai mare în urma comparației dintre ele.
Vom descoperi mai multe despre limbaj pe măsură ce lucrăm cu el.
Puteți găsi mai multe exemple aici: https://colab.research.google.com/drive/1Lxed6J79CsWwyrr8vpLugTmS6GMwMA-j?usp=drive_link
Sau în documentația limbajului: https://docs.python.org/3/
Regex
Un RegEx reprezintă o Expresie Regulată (codificarea unei secvențe de caractere). Poate fi folosit pentru a identifica secvențe de caractere într-un șir, pentru a înlocui secvențe sau pentru a separa un șir în funcție de diferite metrici. O secvență de căutare arată așa:
import re
txt = "The rain in Spain stays mainly in the plain"
x = re.search("Spain", txt)
if x:
print("Cuvântul există în șir")
else:
print("Cuvântul nu există în șir")
Output: Cuvântul există în șir
Există o serie de reguli și simboluri pe care le putem folosi pentru a descrie secvența de caractere căutată. O să modificăm exemplul original pentru a ne uita la câteva exemple.
Putem pune [.] în pozițiile în care poate fi orice caracter, [^] este caracterul început de șir și [$] este caracterul pentru final de șir.
print(re.findall("Sp.in", txt))
print(re.findall("^The rain in Spain stays mainly in the plain$", txt))
Output:
['Spain']
['The rain in Spain stays mainly in the plain']
Dacă punem [+] după un caracter acela trebuie să apară minim o dată. Dacă punem [*] după un caracter, acela poate să apară de oricâte ori, chiar și 0. Simbolurile pot fi combinate: [.+] înseamnă că putem avea o listă de caractere oricât de lungă.
x = re.findall(".*ai", txt)
print(x)
Output: ['The rain in Spain stays mainly in the plai']
În loc de a folosi [.+] putem folosi secvențe specifice:
- \d identifică o listă de cifre
- \D - caractere care nu sunt cifre
- \s - caracterul spațiu
- \w - litere mici și mari, cifre și caracterul “_”
Pentru a fi și mai specifici putem folosi seturi:
- [ar] - cel puțin unul din caracterele “a” și “r” este prezent
- [a-n] - orice caracter lowercase din intervalul dat
- [0-9] - putem aplica intervalele și pentru cifre
- [a-zA-Z] - sau le putem concatena pentru a accepta caractere mai variate
- [1-3][7-9] - două seturi unul în continuarea celuilalt funcționează ca orice alte simboluri legate. Exemplul dat caută o secvență de 2 cifre, unde prima cifră este în intervalul 1-3, iar a doua în intervalul 7-9
Putem folosi secvențele de mai sus pentru a identifica toate cuvintele care conțin șirul “ai”, de exemplu:
x = re.findall("\w*ai\w", txt)
print(x)
Output: ['rain', 'Spain', 'main', 'plain']
Lista completă de reguli și simboluri se află aici: https://docs.python.org/3/library/re.html
EXERCIȚIU
Creează o funcție de preprocesare a textului: funcția va primi un șir de caractere, îl va împărți în cuvinte și va elimina toate caracterele care nu sunt litere. Modifică funcția astfel încât să păstreze cratimele din cuvinte.
txt = "M-am dus la piata - asta voiam? Vom ajunge repede, cred, acasa!"
Python Cheat Sheet
Colabul cu toate funcțiile ajutătoare pentru a învăța Python aici: Python Cheat Sheet
Modelarea Datelor
Codul și exercițiile asociate fișierului curent pot fi accesate aici: Modelarea Datelor
Probleme de căutare
Colabul cu teoria și problemele specifice acestui capitol sunt disponibile aici: Probleme de căutare
Algoritmul A*
Algoritmul A* se folosește pentru a găsi un drum de cost minim de la un nod-start la un nod-scop într-un graf ponderat.
Informații generale
Date de intrare:
- graful (nodurile, muchiile împreună cu costurile lor)
- nodul din care începe căutarea (nodul-start)
- un scop dat sub forma unei condiții pe care trebuie să o îndeplinească nodul căutat (se poate oferi chiar nodul propriu-zis, condiția fiind relația de egalitate cu acest nod). Vom numi mai departe nodul care îndeplinește condiția nod-scop
- o estimare (euristică) a costului de la fiecare nod din graf la nodul (nodurile) scop.
Notații:
- $f$ - costul unui drum
- $\hat{f}$ - costul estimat al unui drum
- $g(nod_c)$ - costul unui drum de cost minim de la nodul start la un nod curent, $nod_c$, din drum
- $h(nod_c)$ - costul efectiv al drumului de cost minim de la nodul curent la nodul scop pe un anumit drum
- $\hat{h}(nod_c)$ - costul estimat de la nodul curent la nodul scop (euristica)
Pentru un drum dat D, avem formula: $f_D$ = $g_D(nod_c$) + $h_D(nod_c$), unde $nod_c$ e un nod din drumul D
Deoarece pe parcursul construirii arborelui de parcurgere nu cunoaștem costul adevărat de la nodul curent la nodul scop (graful fiind descoperit pe măsura ce e parcurs), ne vom folosi în algoritm de formula costului estimat: $\hat{f}_D$ = $g_D$($nod_c$) + $\hat{h}_D$($nod_c$).
Admisibilitate:
Spunem că euristica este admisibilă dacă îndeplinește condiția: $\hat{h}(nod) \leq h(nod)$
Regula de consistență:
Având o muchie $n_1 \rightarrow n_2$, euristica calculată în nodul $n_1$ trebuie să fie mai mică sau egală decât costul muchiei $n_1 \rightarrow n_2$ adunat la euristica nodului $n_2$
$\hat{h}(n1) \leq cost(n1 \rightarrow n2) + \hat{h}(n2)$
Pașii algoritmului
Se consideră două liste: OPEN (cu nodurile descoperite care înca nu au fost expandate) și CLOSED (cu nodurile descoperite și expandate).
- În lista open se pune la început doar nodul de pornire.
- Inițial lista closed e vidă
- Cât timp lista open nu e vidă se execută repetitiv pașii următori:
- Se extrage primul nod, n, din lista open și se pune în closed.
- Dacă nodul n este nod scop, se oprește căutarea și se afișează drumul de la nodul-start până la nodul n.
- Se extinde nodul n, obținând succesorii lui în graf. Nu se vor lua în considerare succesorii care se află în drumul de la nodul start la n. Toți succesorii îl au ca părinte pe n. Toți succesorii care nu se află deja în open sau closed sunt inserați în lista open astfel încât aceasta să fie în continuare ordonată crescător dupa f.
- Pentru succesorii care sunt deja în open sau closed, în cazul în care pentru drumul care trece prin n, s-a obținut un f mai mic, li se schimbă părintele în n și li se actualizează f-ul, iar nodurile din open sunt repoziționate în lista astfel încât să rămână ordonată crescător după f.
- Pentru nodurile din closed (care au fost deja expandate) ar trebui refăcut calculul pentru nodurile succesoare lor, prin urmare cel mai simplu este să le readăugăm direct în open.
Implementare
Pentru implementare putem considera niște clase ajutătoare, care ar fi adaptate la particularitățile problemei curente rezolvate cu A*.
Clasa Nod reprezintă clasa prin care se memorează informațiile despre nodurile din graf. Poate avea următoarele proprietăți:
- informație - referință către informația nodului
- părinte - referință către nodul-părinte din arbore. Pentru rădăcina arborelui, părintele va avea valoarea None.
- g - costul de la rădăcina arborelui până la nodul curent
- f - costul estimat pentru drumul care pornește de la rădăcină și trece prin nodul curent
- h - estimarea făcuta pentru nod (valoarea funcției euristice pentru nod)
și următoarele metode:
- expandează / succesori - care va returna o listă cu toți succesorii posibili ai nodului curent
- scop - care testează dacă nodul e nod scop
Exerciții
Exercițiile acestui capitol sunt accesibile aici: A Star
MinMax
Algoritmul MinMax se folosește pentru a determina cea mai bună mutare într-un 0-sum game cu 2 jucători.
Informații generale
Date de intrare:
- graful (nodurile, muchiile împreună cu costurile lor)
- nodul din care începe căutarea (nodul-start)
- un scop dat sub forma unei condiții pe care trebuie să o îndeplinească nodul căutat (se poate oferi chiar nodul propriu-zis, condiția fiind relația de egalitate cu acest nod). Vom numi mai departe nodul care îndeplinește condiția nod-scop
- o estimare (euristică) a costului de la fiecare nod din graf la nodul (nodurile) scop.
Pașii algoritmului
Paşi:
-
Generează arborele de joc până la stările scop sau o adâncime stabilită.
-
Estimează scorul fiecărei stări terminale (frunză).
-
Deplasează-te înapoi în arbore, de la nodurile frunze spre nodul rădăcină, determinând la fiecare nivel al arborelui valorile care reprezintă utilitatea (i.e. scorul) nodurilor aflate la acel nivel. Propagarea acestor valori la nivelurile anterioare se face prin intermediul nodurilor-părinte conform următoarei reguli:
- dacă părintele este un nod de tip MAX, atribuie-i maximul dintre valorile fiiilor săi;
- dacă părintele este un nod de tip MIN, atribuie-i minimul dintre valorile fiilor săi.
-
Ajuns în nodul-rădăcină, alege pentru MAX mutarea care îl conduce către cel mai mare scor.
Exemplu
Fie imaginea de mai jos:
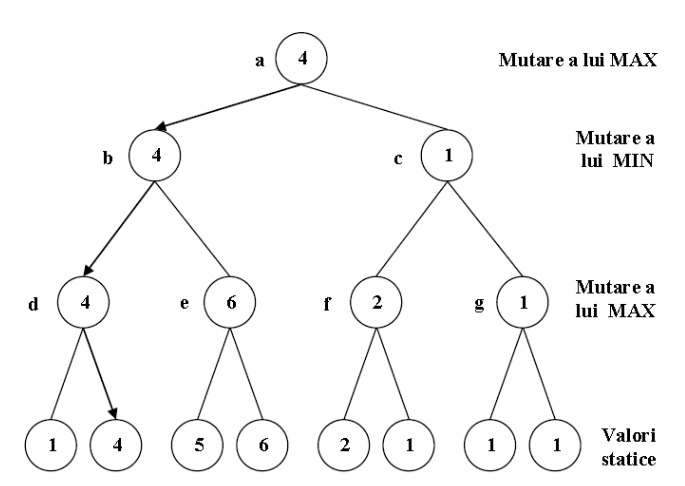
Cât va fi valoarea din rădăcină după ce rulăm MinMax pe exemplul din imagine?
Slide-uri cu soluția și toți pașii algoritmului
Exerciții
Exercițiile acestui capitol sunt accesibile aici: MinMax
Proiect
Connect 4
Connect 4 se joacă pe o tablă cu 6 linii și 7 coloane. ei doi jucători joacă pe rând, plasând câte o piesă la fiecare mutare.
La tura sa, jucătorul alege o coloană care nu este plină și își lasă piesa să cadă pe cel mai de jos loc liber din acea coloană. Coloanele se completează mereu de jos în sus.
Jocul se încheie atunci când unul dintre jucători reușește să formeze o linie de patru piese consecutive de aceeași culoare, fie pe orizontală, fie pe verticală, fie pe diagonală.
Link joc: https://papergames.io/en/connect4
WordNet
Codul și exercițiile asociate fișierului curent pot fi accesate aici: WordNet
Procesare de Text
Codul și exercițiile asociate fișierului curent pot fi accesate aici: Introducere în Procesare de Text
Chatbot
Exercițiile acestui capitol sunt accesibile aici: Chatbot
Proiect
Chatbot
Antrenați un chatbot specializat pe orice domeniu.
Pregătiți un poster în care să prezentați acest chatbot.
Elemente de Bază în Inteligența Artificială
Numim Inteligență Artificială orice program care implementează o soluție pentru o problemă de care în mod normal se ocupă un om, deoarece necesită un minim de inteligență. Asta înseamnă că în categoria de AI intră atât programe care se pot juca X & 0 cu un utilizator pe baza unui algoritm euristic, cât și programe mai complexe, bazate pe Machine Learning.
Machine Learning se referă la programele cărora nu le spunem cum să rezolve o problemă, ci doar ce vrem să se întâmple. Asta înseamnă că le lăsăm să își descopere propriul set de reguli probabilistic, bazat pe exemple.
Putem considera că problemele de mai sus se pot rezolva cu programe care necesită maxim 2 dimensiuni: pentru fiecare datapoint primit la intrare selectăm o serie de caracteristici și extragem eticheta (label-ul) acestuia. Zona de Deep Learning folosește mai multe dimensiuni. Pentru fiecare datapoint pornim cu același set de caracteristici și încercăm să ajungem la aceeași etichetă, dar trecem prin mult mai multe straturi de procesare pe parcurs. Despre aceste straturi vom vorbi mai târziu.
De ce Inteligență Artificială?
- e la modă
- e de actualitate
- ne face viața mai simplă
- …
Cu ce putem combina IA?
- biologie
- lingvistică
- psihologie
- matematică aplicată (mai ales statistică și probabilități)
- algoritmi
- …
Antrenarea unui model
Un algoritm de ML trece prin 3 stări: reprezentare, evaluare, optimizare. Partea de reprezentare ne ajută să alegem modelul corect pentru a rezolva o problemă? Optimizarea o facem constant, pe măsură ce încercăm diverse features* sau hiperparametri** pe un model. Pentru evaluare vom folosi momentan acuratețea: număr de teste corecte / număr total de teste. Pe viitor vom detalia tipurile de măsurători și când o folosim pe fiecare.
*Features = informații în plus despre setul nostru de date care ar putea ajuta modelul să invețe mai bine
**Hiperparametri = parametrii pe care îi primește modelul nostru la antrenare
Există mai multe tipuri de învățare automată:
- Învățare supervizată (supervised learning)
- Învățare nesupervizată (unsupervised learning)
- Învățare semi-supervizată (semi-supervised learning)
- Învățare activă (active learning)
- Învățare prin transfer (transfer learning)
În acest modul vom discuta doar despre primele 2 metode.
Supervised vs. Unsupervised Learning
Învățarea supervizată implică să cunoaștem de la început seria de labeluri posibile pentru taskul nostru. Învățarea nesupervizată se bazează pe faptul că modelul nostru își va genera propriile clase (fără să le dea nume) în funcție de anumite observații pe care le face pe parcurs.
De exemplu, o problemă de învățare supervizată este clasificarea imaginilor în câini, pisici, sau other. Care ar fi un task nesupervizat pentru aceeași problemă?
Exemple de probleme pentru care putem folosi învățarea supervizată:
- Recunoașterea cifrelor scrise de mână
- Detecție facială: marcarea fiecărei fețe cu un dreptunghi colorat pe imagine
- Detecția mailurilor tip spam
- Prezicerea prețului acțiunilor la bursă
Dați exemplu de task nesupervizat echivalent fiecărui task de mai sus. Cum ați rezolvă fiecare din aceste probleme fără inteligență artificială?
Supervised Models
Regression vs. Classification
Problemele de învățare supervizată se împart în 2 categorii:
- Probleme de clasificare
- Probleme de regresie
Diferența este intuitivă: în cazul problemelor de clasificare labelurile sunt independente, ceea ce înseamnă că răspunsul nostru poate fi doar corect sau greșit. În cazul problemelor de regresie ne interesează să fim cât mai aproape de răspunsul corect, așadar acuratețea este măsurată ca o diferență.
Determinarea vârstei unei persoane este o problemă de clasificare sau de regresie?
Pentru fiecare exemplu de la exercițiul anterior, stabiliți dacă este un task de clasificare sau de regresie.
Unsupervised Models
Folosim modele unsupervised atunci când vrem să împărțim setul de date în mai multe categorii, dar nu avem datele labeled sau categoriile precizate de la început (ex: împărțim poze cu câini în funcție de rasa acestora).
După ce modelul împarte datele în categorii trebuie să ne uităm la categoriile create și să decidem dacă vrem să le păstrăm așa sau încercăm alt labeling, iar dacă ne place ne rămâne nouă să dăm labelurile.
Aceste modele sunt utile pentru o primă filtrare de date sau dacă vrem o adnotare rapidă, pe care putem aranja noi datele după.
1. Clustering
Se bazează pe gruparea datelor în diverse categorii. Grupările pot fi bazate pe:
- un centroid: K-means
- ierarhii: AgglomerativeClustering
- densitate: DBSCAN
- distribuție: Gaussian Mixture
- grafuri: HCS
Se poate observa în imaginea de mai jos cum diferite modele funcționează mai bine în funcție de distribuția datelor:
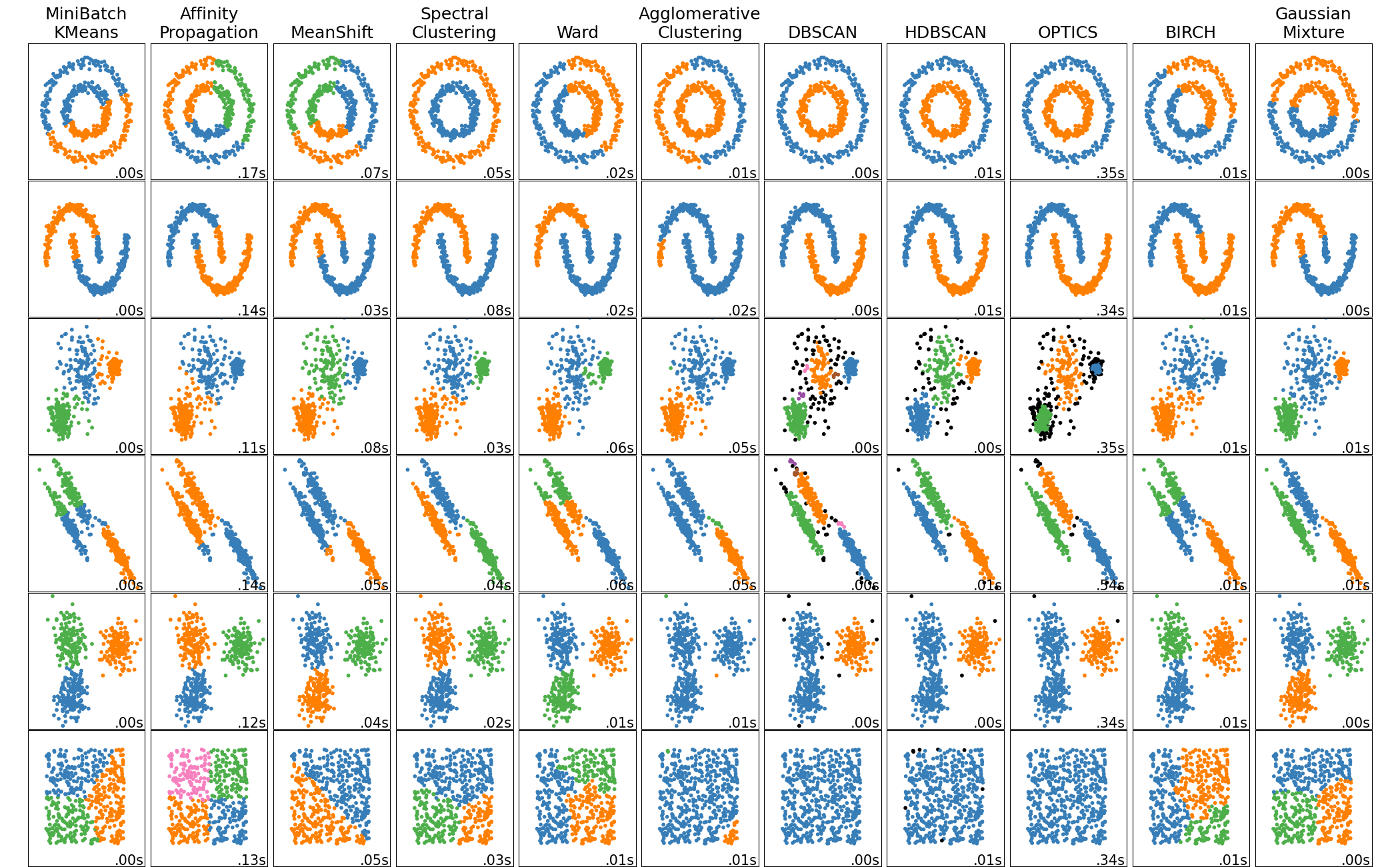
Sursă imagine și comparație modele
Cum începem?
În următoarele capitole veți învăța despre cum funcționează cele mai comune modele de Machine Learning. Asta nu înseamnă că tu va trebui să le implementezi vreodată! Ele sunt deja implementate în librăriile cunoscute, iar tu va trebui doar să le apelezi pe setul tău de date. Orice modificare relevantă ai putea face pe aceste modele este, de cele mai multe ori, un parametru pe care îl poți seta.
Asta nu înseamnă că nu ar trebui să le implementezi niciodată. Noi recomandăm să încercați să scrieți de la 0 toate modelele măcar o dată ca să vă asigurați că ați înțeles cum funcționează.
De ce m-ar interesa cum funcționează un model? Ca să știi ce să folosești la fiecare problemă. În funcție de informațiile pe care le știm despre un set de date ne așteptăm ca anumite modele să funcționeze mai bine decât altele.
În colab-ul asociat acestei secțiuni vei găsi un template de cod pe care îl vei putea folosi fix așa în cele mai multe situații. Hai să trecem puțin prin el:
import pandas as pd
De cele mai multe ori în ML vom primi setul de date sub formă de tabel. Pandas este un exemplu de librărie care poate să citească, modifice și creeze ușor fișiere care respectă acest format (.csv, .xls etc.)
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
Datele de antrenare (train) și test vor fi date în enunțul problemei. Motivul pentru care antrenăm modelele pe anumite date e ca să le putem utiliza ulterior în aplicații în viața reală. Asta înseamnă că în momentul în care am decis că suntem mulțumiți cu performanța lui pe date pentru care știm răspunsul corect (train) îl putem folosi pentru a afla răspunsul la întrebări noi (test). Datele de test nu vor avea niciodată coloana de labels publică întrucât încearcă să simuleze viața reală. Aceea este folosită doar de evaluatorul problemei pentru a-ți cuantifica performanța.
from sklearn.model_selection import train_test_split
label = 'Numele coloanei cu răspunsuri'
train, validation = train_test_split(df_train, test_size=0.2, random_state=0)
y_train = train[label]
X_train = train.drop(columns=[label])
y_validation = validation[label]
X_validation = validation.drop(columns=[label])
Întrucât noi nu știm labelurile datelor de test vom avea nevoie să ne simulăm aceleași condiții local pentru a ajunge la cel mai bun răspuns. Urmează să testăm diverse procesări de date și modele, dar ca să ne dăm seama care e cel mai bun va trebui să simulăm și noi, local, aceleași condiții din viața reală pe care le simulează evaluatorul. Din fericire, de cele mai multe ori este suficient să ne împărțim datele în 2 (train și validation), să antrenăm pe noul train și să comparăm rezultatele obținute de modelul nostru pe datele de validare cu rezultatele reale pe aceste date.
# CORECTARE / CURATARE DATE
Nu vom scrie cuvintele de mai sus în cod, dar va trebui să ne asigurăm că toate datele noastre sunt numerice, nu există elemente de tip None etc.
from sklearn.metrics import accuracy_score
model = ClasaDeModele()
model = model.fit(X_train, y_train)
y_pred = model.predict(X_validation)
print(accuracy_score(y_pred, y_validation))
Cam așa o să arate antrenarea pe care o faci, indiferent de model. Înlocuim ClasaDeModele cu clasa care conține modelul pe care vrem să îl folosim, antrenăm acest model pe datele de train, prezicem răspunsurile sale pe datele de validare și analizăm cât de bine s-a descurcat.
Metrica folosită în exemplu (acuratețea) numără câte răspunsuri corecte a dat modelul împărțit la numărul total de întrebări – deci rezultatul va fi un număr între 0 și 1, unde 1 înseamnă că s-a descurcat perfect.
df_test[label] = model.predict(df_test)
df_test.rename(columns={'Unnamed: 0': 'ID'})
df_test[['ID', label]].to_csv('prediction.csv', index=False)
După ce am terminat antrenare îmi pot salva predicțiile pe datele de test într-un csv. Unele platforme necesită ca outputul să aibă fix 2 coloane - ID și predicție - așa că am denumit corect coloana ID (în cazul în care nu era deja denumită astfel) și am adăugat coloana cu predicțiile. Acum poți trimite codul să vezi cum te-ai descurcat!
Regresie
Codul și exercițiile asociate fișierului curent pot fi accesate aici: Introducere în Regresie
Algoritmi Probabilistici
Codul și exercițiile asociate fișierului curent pot fi accesate aici: Introducere în Algoritmi Probabilistici
K Nearest Neighbors
Codul și exercițiile asociate fișierului curent pot fi accesate aici: K Nearest Neighbors
Video Pregătire Nitro AI: https://www.youtube.com/watch?v=QJHdyQ4W8v4
Colab Teorie Nitro AI: https://drive.google.com/file/d/15kMCjyinBPxkfl6Dm_NX8Vqu9lzHMZeq/view?usp=sharing
Colab Titanic Nitro AI: https://drive.google.com/file/d/1noYS8h8Y8dVFLty_lsLonTvJ-RNkXf0l/view?usp=sharing
K-Means
Codul și exercițiile asociate fișierului curent pot fi accesate aici: K-Means
Arbori de Decizie
Codul și exercițiile asociate fișierului curent pot fi accesate aici: Arbori de Decizie
Metrici & Scalări
Codul și exercițiile asociate fișierului curent pot fi accesate aici: Metrici & Scalări
Proiect
Alegeți un set de date pe clasificare de text cu 2 clase. Analizați setul de date, preprocesări, hiperparametri etc. (cum am făcut până acum) și pregătiți o prezentare powerpoint de 5 minute în care explicați ce ați încercat, ce ați observat, ce concluzii ați tras la final (ce funcționează cel mai bine și de ce?).
Puteți alege un set de date de aici: