Elemente de Bază în Inteligența Artificială
Numim Inteligență Artificială orice program care implementează o soluție pentru o problemă de care în mod normal se ocupă un om, deoarece necesită un minim de inteligență. Asta înseamnă că în categoria de AI intră atât programe care se pot juca X & 0 cu un utilizator pe baza unui algoritm euristic, cât și programe mai complexe, bazate pe Machine Learning.
Machine Learning se referă la programele cărora nu le spunem cum să rezolve o problemă, ci doar ce vrem să se întâmple. Asta înseamnă că le lăsăm să își descopere propriul set de reguli probabilistic, bazat pe exemple.
Putem considera că problemele de mai sus se pot rezolva cu programe care necesită maxim 2 dimensiuni: pentru fiecare datapoint primit la intrare selectăm o serie de caracteristici și extragem eticheta (label-ul) acestuia. Zona de Deep Learning folosește mai multe dimensiuni. Pentru fiecare datapoint pornim cu același set de caracteristici și încercăm să ajungem la aceeași etichetă, dar trecem prin mult mai multe straturi de procesare pe parcurs. Despre aceste straturi vom vorbi mai târziu.
De ce Inteligență Artificială?
- e la modă
- e de actualitate
- ne face viața mai simplă
- …
Cu ce putem combina IA?
- biologie
- lingvistică
- psihologie
- matematică aplicată (mai ales statistică și probabilități)
- algoritmi
- …
Antrenarea unui model
Un algoritm de ML trece prin 3 stări: reprezentare, evaluare, optimizare. Partea de reprezentare ne ajută să alegem modelul corect pentru a rezolva o problemă? Optimizarea o facem constant, pe măsură ce încercăm diverse features* sau hiperparametri** pe un model. Pentru evaluare vom folosi momentan acuratețea: număr de teste corecte / număr total de teste. Pe viitor vom detalia tipurile de măsurători și când o folosim pe fiecare.
*Features = informații în plus despre setul nostru de date care ar putea ajuta modelul să invețe mai bine
**Hiperparametri = parametrii pe care îi primește modelul nostru la antrenare
Există mai multe tipuri de învățare automată:
- Învățare supervizată (supervised learning)
- Învățare nesupervizată (unsupervised learning)
- Învățare semi-supervizată (semi-supervised learning)
- Învățare activă (active learning)
- Învățare prin transfer (transfer learning)
În acest modul vom discuta doar despre primele 2 metode.
Supervised vs. Unsupervised Learning
Învățarea supervizată implică să cunoaștem de la început seria de labeluri posibile pentru taskul nostru. Învățarea nesupervizată se bazează pe faptul că modelul nostru își va genera propriile clase (fără să le dea nume) în funcție de anumite observații pe care le face pe parcurs.
De exemplu, o problemă de învățare supervizată este clasificarea imaginilor în câini, pisici, sau other. Care ar fi un task nesupervizat pentru aceeași problemă?
Exemple de probleme pentru care putem folosi învățarea supervizată:
- Recunoașterea cifrelor scrise de mână
- Detecție facială: marcarea fiecărei fețe cu un dreptunghi colorat pe imagine
- Detecția mailurilor tip spam
- Prezicerea prețului acțiunilor la bursă
Dați exemplu de task nesupervizat echivalent fiecărui task de mai sus. Cum ați rezolvă fiecare din aceste probleme fără inteligență artificială?
Supervised Models
Regression vs. Classification
Problemele de învățare supervizată se împart în 2 categorii:
- Probleme de clasificare
- Probleme de regresie
Diferența este intuitivă: în cazul problemelor de clasificare labelurile sunt independente, ceea ce înseamnă că răspunsul nostru poate fi doar corect sau greșit. În cazul problemelor de regresie ne interesează să fim cât mai aproape de răspunsul corect, așadar acuratețea este măsurată ca o diferență.
Determinarea vârstei unei persoane este o problemă de clasificare sau de regresie?
Pentru fiecare exemplu de la exercițiul anterior, stabiliți dacă este un task de clasificare sau de regresie.
Unsupervised Models
Folosim modele unsupervised atunci când vrem să împărțim setul de date în mai multe categorii, dar nu avem datele labeled sau categoriile precizate de la început (ex: împărțim poze cu câini în funcție de rasa acestora).
După ce modelul împarte datele în categorii trebuie să ne uităm la categoriile create și să decidem dacă vrem să le păstrăm așa sau încercăm alt labeling, iar dacă ne place ne rămâne nouă să dăm labelurile.
Aceste modele sunt utile pentru o primă filtrare de date sau dacă vrem o adnotare rapidă, pe care putem aranja noi datele după.
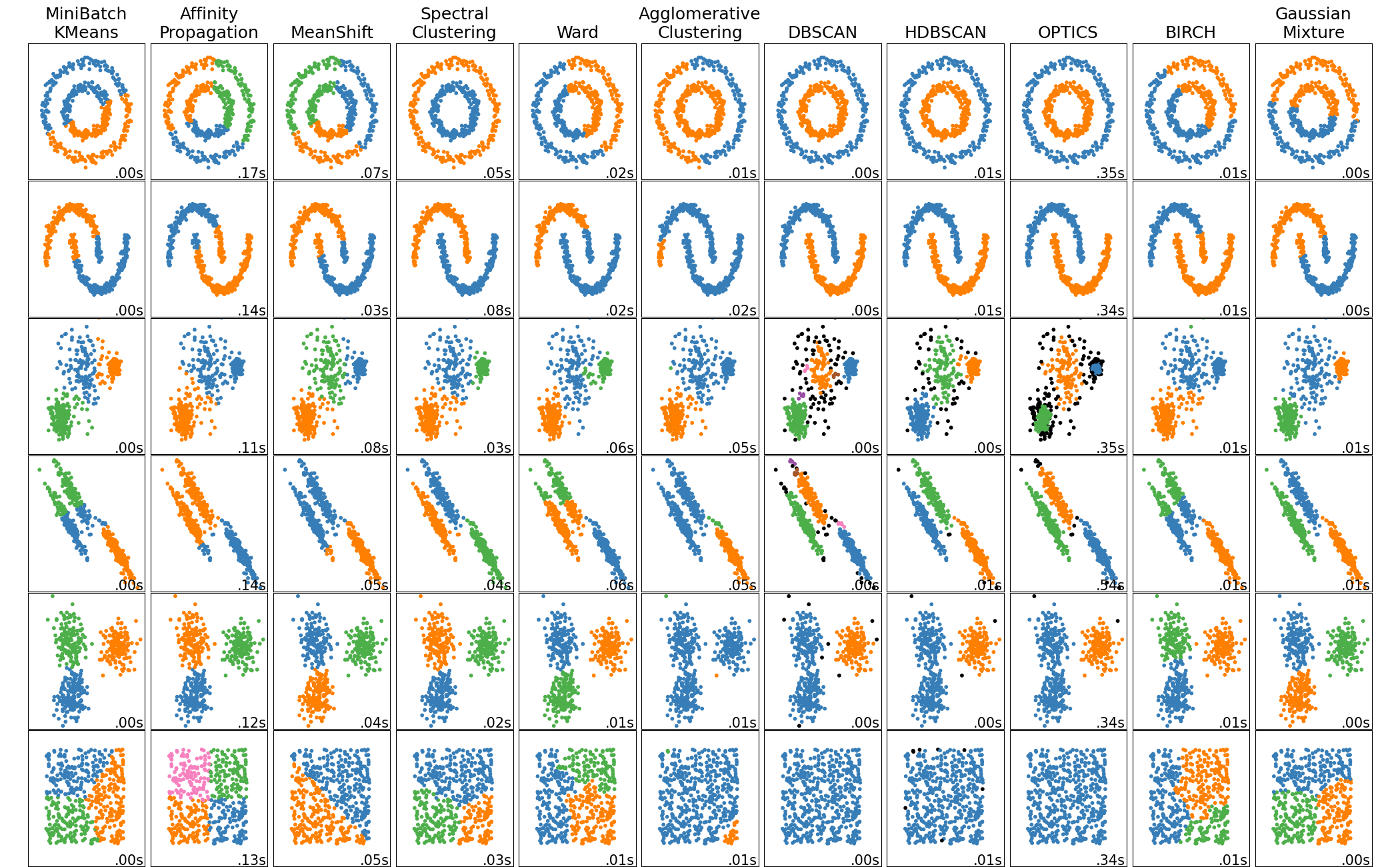
1. Clustering
Se bazează pe gruparea datelor în diverse categorii. Grupările pot fi bazate pe:
- un centroid: K-means
- ierarhii: AgglomerativeClustering
- densitate: DBSCAN
- distribuție: Gaussian Mixture
- grafuri: HCS
Se poate observa în imaginea de mai jos cum diferite modele funcționează mai bine în funcție de distribuția datelor: